CSCI 4717: Direct Mapping Cache Assignment
As you will recall, we discussed three cache mapping functions, i.e.,
methods of addressing to locate data within a cache.
- Direct
- Full Associative
- Set Associative
Each of these depends on two facts:
- RAM is divided into blocks of memory locations. In other words, memory locations
are grouped into blocks of 2n locations where n represents the
number of bits used to identify a word within a block. These n bits are found
at the least-significant end of the physical address. The image below has
n=2 indicating that for each block of memory, there are 22 = 4
memory locations.
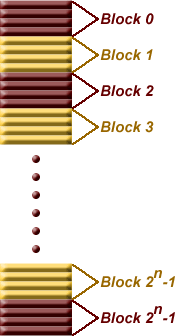
Therefore, for this example, the least two significant bits of an address
indicate the location within a block while the remaining bits indicate the
block number. The table below shows an example with a 20 bit address with
four words per block. Notice that for each group of four words, the word bits
take on each of the four possible values allowed with 2 bits while the block
identification bits remain constant.,
|
Block
|
Address
|
Block identification bits
|
Word bits
|
|
Block 0
|
0x00000
|
0000 0000 0000 0000 00
|
00
|
|
0x00001
|
0000 0000 0000 0000 00
|
01
|
|
0x00002
|
0000 0000 0000 0000 00
|
10
|
|
0x00003
|
0000 0000 0000 0000 00
|
11
|
|
Block 1
|
0x00004
|
0000 0000 0000 0000 01
|
00
|
|
0x00005
|
0000 0000 0000 0000 01
|
01
|
|
0x00006
|
0000 0000 0000 0000 01
|
10
|
|
0x00007
|
0000 0000 0000 0000 01
|
11
|
|
Block 2
|
0x00008
|
0000 0000 0000 0000 10
|
00
|
|
0x00009
|
0000 0000 0000 0000 10
|
01
|
|
0x0000A
|
0000 0000 0000 0000 10
|
10
|
|
0x0000B
|
0000 0000 0000 0000 10
|
11
|
|
Block 3
|
0x0000C
|
0000 0000 0000 0000 11
|
00
|
|
0x0000D
|
0000 0000 0000 0000 11
|
01
|
|
0x0000E
|
0000 0000 0000 0000 11
|
10
|
|
0x0000F
|
0000 0000 0000 0000 11
|
11
|
|
And so on...until we get to the last row
|
|
Block 2n-1
|
0xFFFFC
|
1111 1111 1111 1111 11
|
00
|
|
0xFFFFD
|
1111 1111 1111 1111 11
|
01
|
|
0xFFFFE
|
1111 1111 1111 1111 11
|
10
|
|
0xFFFFF
|
1111 1111 1111 1111 11
|
11
|
- The cache is organized into lines, each of which contains enough
space to store exactly one block of data and a tag uniquely identifying where
that block came from in memory.
As far as the mapping functions are concerned, the book did an okay job describing
the details and differences of each. I, however, would like to describe them
with an emphasis on how we would model them using code.
Direct Mapping
Remember that direct mapping assigned each memory block to a specific line
in the cache. If a line is all ready taken up by a memory block when a new block
needs to be loaded, the old block is trashed. The figure below shows how multiple
blocks are mapped to the same line in the cache. This line is the only line
that each of these blocks can be sent to. In the case of this figure, there
are 8 bits in the block identification portion of the memory address.
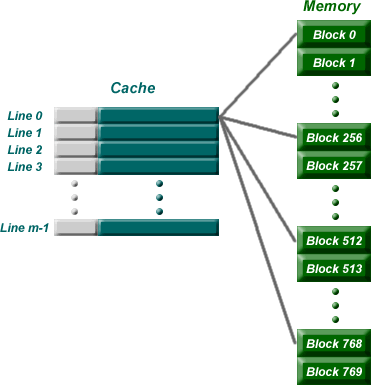
The address for this example is broken down something like the following:
|
Tag
|
8 bits identifying line in cache
|
word id bits
|
Once the block is stored in the line of the cache, the tag is copied to the
tag location of the line.
Direct Mapping Summary
The address is broken into three parts: (s-r) MSB bits represent the tag to
be stored in a line of the cache corresponding to the block stored in the line;
r bits in the middle identifying which line the block is always stored in; and
the w LSB bits identifying each word within the block. This means that:
- The number of addressable units = 2s+w words or bytes
- The block size (cache line width not including tag) = 2w words
or bytes
- The number of blocks in main memory = 2s (i.e., all the bits
that are not in w)
- The number of lines in cache = m = 2r
- The size of the tag stored in each line of the cache = (s - r) bits
Direct mapping is simple and inexpensive to implement, but if a program accesses
2 blocks that map to the same line repeatedly, the cache begins to thrash back
and forth reloading the line over and over again meaning misses are very high.
Full Associative Mapping
In full associative, any block can go into any line of the cache. This means
that the word id bits are used to identify which word in the block is needed,
but the tag becomes all of the remaining bits.
Full Associative Mapping Summary
The address is broken into two parts: a tag used to identify which block is
stored in which line of the cache (s bits) and a fixed number of LSB bits identifying
the word within the block (w bits). This means that:
- The number of addressable units = 2s+w words or bytes
- The block size (cache line width not including tag) = 2w words
or bytes
- The number of blocks in main memory = 2s (i.e., all the bits
that are not in w)
- The number of lines in cache is not dependent on any part of the memory
address
- The size of the tag stored in each line of the cache = s bits
Set Associative Mapping
This is the one that you really need to pay attention to because this is the
one for the homework. Set associative addresses the problem of possible thrashing
in the direct mapping method. It does this by saying that instead of having
exactly one line that a block can map to in the cache, we will group a few lines
together creating a set. Then a block in memory can map to any
one of the lines of a specific set. There is still only one set that the block
can map to.
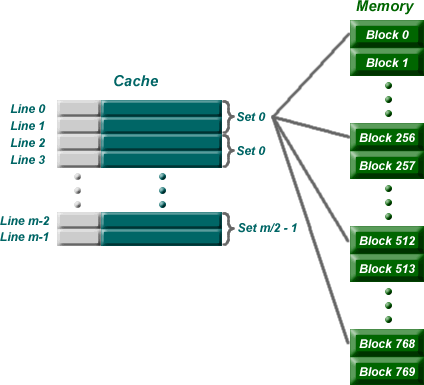
Note that blocks 0, 256, 512, 768, etc. can only be mapped to one set. Within
the set, however, they can be mapped associatively to one of two lines.
The memory address is broken down in a similar way to direct mapping except
that there is a slightly different number of bits for the tag (s-r) and the
set identification (r). It should look something like the following:
|
Tag (s-r bits)
|
set identifier (r bits)
|
word id (w bits)
|
Now if you have a 24 bit address in direct mapping with a block
size of 4 words (2 bit id) and 1K lines in a cache (10 bit id), the partitioning
of the address for the cache would look like this.
Direct Mapping Address Partitions
|
Tag (12 bits)
|
line identifier (10 bits)
|
word id (2 bits)
|
If we took the exact same system, but converted it to 2-way set associative
mapping (2-way meaning we have 2 lines per set), we'd get the following:
|
Tag (13 bits)
|
line identifier (9 bits)
|
word id (2 bits)
|
Notice that by making the number of sets equal to half the number of lines
(i.e., 2 lines per set), one less bit is needed to identify the set within the
cache. This bit is moved to the tag so that the tag can be used to identify
the block within the set.
Homework Assignment
Your assignment is to simulate a 4K direct mapping cache
using C. The memory of this system is divided into 8-word blocks, which means
that the 4K cache has 4K/8 = 512 lines. I've given you two function declarations
in C. In addition, I've given you two arrays, one representing chars stored
in main memory and one representing the lines of the cache. Each line is made
up of a structure called "cache_line". This structure contains all
of the information stored in a single line of the cache including the tag and
the eight words (one block) contained within a single block.
typedef struct
{
int tag;
char block[8];
}cache_line;
An array is made up of these lines called "cache" and it contains
512 lines.
cache_line cache[512];
Next, a memory has been created called "memory". It contains 64K
bytes.
char memory[65536];
There will also be two global variables, int number_of_requests
and int number_of_hits. The purpose of these variables
will be discussed later.
Using this information, you should be able to see that there are 16 bits in
a memory address (216 = 65,536), 3 bits of which identify a word
(char) within a block, 9 bits identify the line that a block should be stored
in, and the remaining 16-3-9=4 bits to store as the tag. Each of these arrays
are global so your routines will simply modify them.
You will be creating two functions with the following prototypes. (Be sure
to use the exact prototypes shown below.)
int requestMemoryAddress(unsigned int address);
unsigned int getPercentageOfHits(void);
requestMemoryAddress() takes as its parameter "address"
a 16-bit value (0 to 65,535) and checks if the word it points to in memory exists
in the cache. If it does, return the value found in the cache. If it doesn't,
load the appropriate line of the cache with the requested block from memory[]
and return a -1 (negative one).
Each time a request is made to requestMemoryAddress(),
increment number_of_requests, and each time one of those requests results in
a TRUE returned, increment number_of_hits. These values will be used in getPercentageOfHits().
This routine is called to see how well the cache is performing. It should return
an integer from 0 to 100 representing the percentage of successful hits in the
cache. The equation should be something like:
number_of_hits
Percentage of hits = -------------------- X 100%
number_of_requests
The data that ends up in cache[] from memory[] won't affect the returned values
of either function, but I will be examining it to see if the correct blocks
of data were moved into the cache[] array.
Well, have fun! Don't hesitate to read the book. There's a great deal of useful
information in there including examples and descriptions of the different mapping
functions.